
Hugging Face Hub is a go-to place for state-of-the-art open source Machine Learning models. However, being a truly open source in that space is not only about exposing the weights under a proper license but also a training pipeline and the data used as an input to this process. Models are only as good as the data used to teach them. But datasets are also valuable for evaluation and benchmarking, and Hugging Face repositories have also become a standard way of exposing them to the public. The datasets library makes downloading a selected dataset in any Python app or notebook convenient.
from datasets import load_dataset
squad_dataset = load_dataset("squad")
Creating your own dataset and publishing it on a Hub is not a big challenge either. No surprise then, that exposing data that way became a standard for sharing it in the community.
Why would anyone want to share a dataset with embeddings?
Embeddings play a crucial role in semantic search applications, including Retrieval Augmented Generation or when we want to incorporate unstructured data into the Machine Learning models. Calculating the embeddings is a bottleneck of any system, as it requires loading possibly huge files (for example, images) and passing them through a neural network. There are multiple scenarios in which we want to share our vectors and allow others to use them directly instead of wasting hours of GPU computing time to process raw data again. It makes sense not only for building demos but also for real apps using publicly available data.
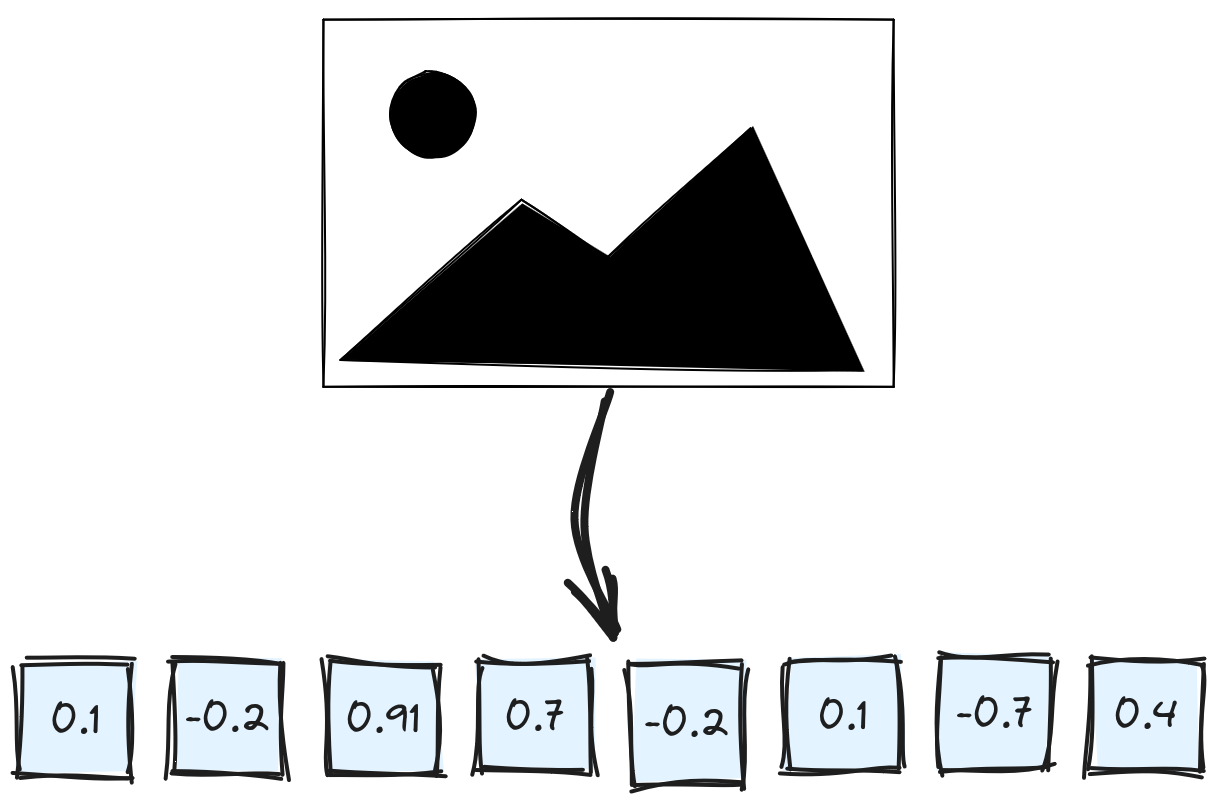
Vector embeddings are just different representations of the data, and we can use them as inputs to other models, for example, to a classifier. However, datasets are usually represented as tabular data, with each row being a single example and columns representing different features. Features are rather scalar values, such as strings or numbers, that we treat atomically. Neural embeddings, in turn, are lists of floats without any specific meaning of a single dimension. An embedding should also be treated as a single feature, which makes some of the supported dataset formats unusable.
Hugging Face supported data formats
There are various options for how to publish a dataset on Hugging Face Hub. The simplest textual formats, such as CSV, JSON, JSONL, or even TXT might be fine enough in some cases, but they have some drawbacks like lack of strict typing or huge memory overhead. SQL databases solve that part, but they usually support scalar types out of the box, and lists of floats don’t suit well here. We could also use a custom format and provide a loading script along the data files, but that comes with an overhead of processing the data each time we want to access it.
Parquet or Arrow seem to be good options if we have a dataset with at least one non-scalar feature, such as embedding, as they natively support complex types. While both are binary columnar formats, they are designed for different purposes. Parquet is an efficient data storage and retrieval format, while Arrow is an in-memory language-independent format for flat and hierarchical data. In general, Arrow and Parquet go well together:
Therefore, Arrow and Parquet complement each other and are commonly used together in applications. Storing your data on disk using Parquet and reading it into memory in the Arrow format will allow you to make the most of your computing hardware.
That being said, sharing a dataset with embeddings using Parquet as a data format seems the best way out, thanks to the native support of complex data types, but also for performance reasons.
Python support for Parquet
Pandas, a standard library for working with dataframes. It might be the first-choice
for many, and it’s usually the easiest way to build a dataset. pandas supports Parquet
if we have one of the backends installed: pyarrow or fastparquet. However, choosing
one of them is not only a matter of performance, but they behave differently in some scenarios.
One of those scenarios is when we want to store compound data types, such as lists.
Let’s define a simple dataframe with embeddings as one of the columns:
import pandas as pd
df = pd.DataFrame({
"id": [1, 2],
"name": ["Alice", "Bob"],
"embedding": [
[1., 2., 3.],
[4., 5., 6.]
],
})
If we try to display the dataframe, we’ll see that the embedding column is printed
as a list of floats, and each vector is indeed stored as list:
print(df)
# Output:
# id name embedding
# 0 1 Alice [1.0, 2.0, 3.0]
# 1 2 Bob [4.0, 5.0, 6.0]
print(type(df["embedding"][0]))
# Output:
# <class 'list'>
We can save it to a Parquet file using fastparquet backend. Then we’ll read it back
and check the data types:
df.to_parquet("/tmp/embeddings.parquet", engine="fastparquet")
df_fastparquet = pd.read_parquet("/tmp/embeddings.parquet")
print(df_fastparquet)
# Output:
# id name embedding
# 0 1 Alice b'[1.0,2.0,3.0]'
# 1 2 Bob b'[4.0,5.0,6.0]'
print(type(df_fastparquet["embedding"][0]))
# Output:
# <class 'bytes'>
Unfortunately, fastparquet struggled with writing a compound data type and converted each
list into bytes, which effectively made the embedding unusable. Doing the same thing, but with
pyarrow engine, gives us the following results:
df.to_parquet("/tmp/embeddings.parquet", engine="pyarrow")
df_pyarrow = pd.read_parquet("/tmp/embeddings.parquet")
print(df_pyarrow)
# Output:
# id name embedding
# 0 1 Alice [1.0, 2.0, 3.0]
# 1 2 Bob [4.0, 5.0, 6.0]
print(type(df_pyarrow["embedding"][0]))
# Output:
# <class 'numpy.ndarray'>
This time our vectors were converted from lists into numpy arrays. It’s better to know
it is going to happen, but should not impact any further processing, as ndarray is also
quite a standard type used for the embeddings.
Generally speaking, using pandas with pyarrow comes with multiple benefits, not only
related to more extensive data types support. The chapter of the pandas documentation on
PyArrow Functionality is a
comprehensive description of the other improvements brought by this integration.
Sharing a dataset with embeddings: best practices
There are various ways in which we can improve the user experience of the datasets we publish. Some of them apply not only to the ones built around embeddings but might be applied in general.
- Make sure you’re allowed to publish the data to the public. Choose the most permissive license possible.
- Use Parquet as your preferred data format for anything beyond toy datasets.
- If you use Python and
pandas, preferpyarrowas the Parquet engine. Datasets Server auto-converts all the Hub datasets to Parquet either way, but it won’t fix the wrong data types. - Divide your dataset into multiple files. It will enable multiprocessing, so people will be able to download the dataset much faster.
- Create a dataset card, so people may find it easily. It’s easiest to do it through the UI.